前言
市面上免费且开源的超融合架构产品可不多,本指南将带你从零开始搭建一个基于Proxmox VE和Ceph的高可用分布式存储系统。即使你是初学者,只要按照步骤操作,也能成功完成部署。
安装前准备
硬件信息
这里采用3台退役的戴尔R730xd服务器来构建一个简单的PVE超融合架构,硬件信息如下: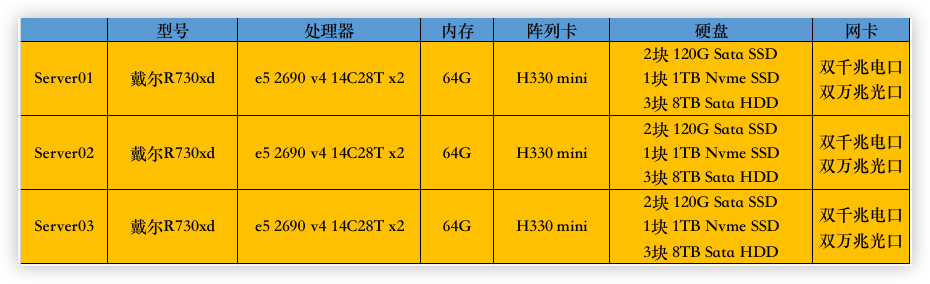
硬件规划
存储方面需要将阵列卡改为hba直通模式,2块后置2.5寸SSD安装PVE(RAID1),3块3.5寸8TB硬盘和1TB扩展nvme卡用于Ceph资源存储。千兆/万兆双网卡分别做端口聚合。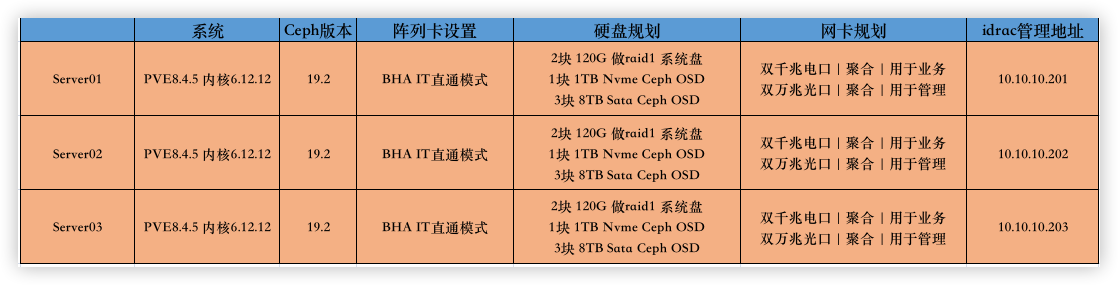
网络规划
本方案部署的网络环境都是可以访问外网的,便于安装和更新以及时间同步。如果你是外网隔离自行解决时间同步和软件安装的问题
| vlan ID | 网段 | 网关 | 用途 |
|---|---|---|---|
| vlan10 | 192.168.10.0/24 | 192.168.10.1 | 用于业务,运行LXC/虚拟机 |
| vlan20 | 192.168.20.0/24 | 192.168.20.1 | 用于管理,PVE内部管理,集群,Ceph |
三台设备网络划分:
| 设备 | 业务网卡(聚合) | 管理网卡(聚合) | 管理地址 | 主机名 |
|---|---|---|---|---|
| server01 | enp6s18 enp6s19 | enp6s20 enp6s21 | 192.168.20.201/24 | R730xd-01 |
| server02 | enp6s18 enp6s19 | enp6s20 enp6s21 | 192.168.20.202/24 | R730xd-02 |
| server03 | enp6s18 enp6s19 | enp6s20 enp6s21 | 192.168.20.203/24 | R730xd-03 |
PVE初始化
安装PVE
将镜像引导启动到PVE安装界面,采用第一种图形化界面进行安装。
PVE系统安装到2块120G硬盘上,RAID1镜像模式安装。PVE图形界面安装示意图: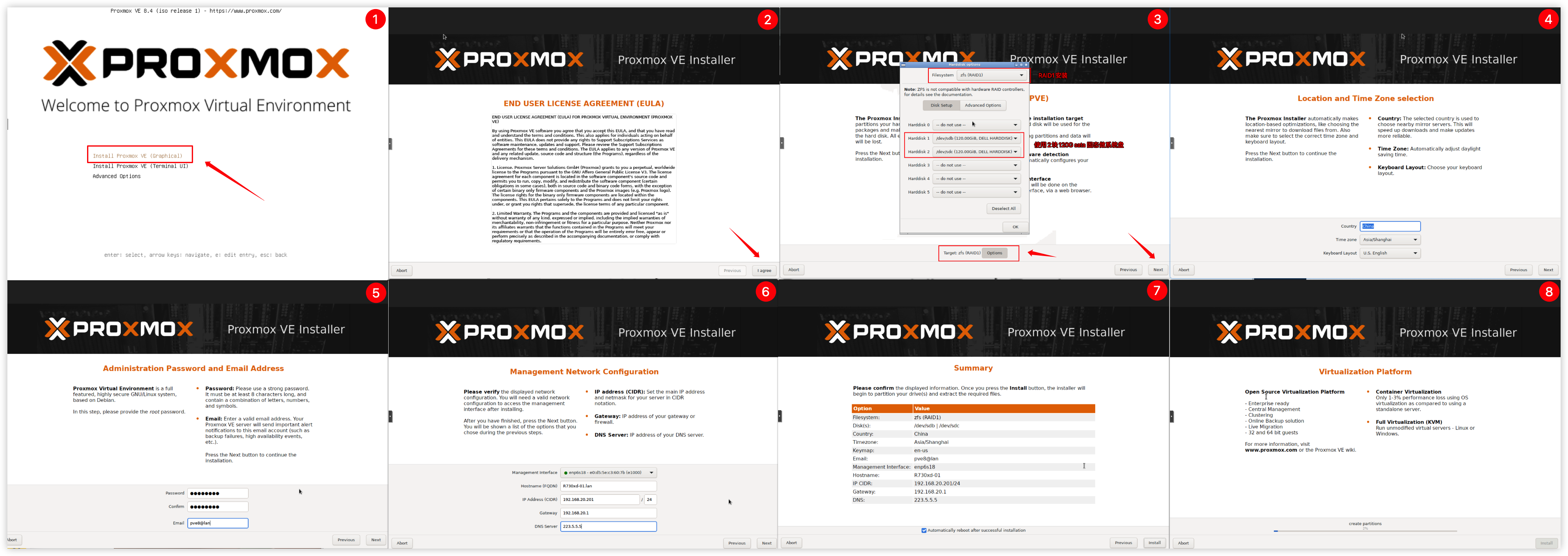
PVE换源
更换系统源
使用nano命令编辑sources.list文件nano /etc/apt/sources.list
# 将原有的源链接在句首加 # 注释掉,更换以下清华源信息
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-updates main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-backports main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian-security bookworm-security main contrib non-free non-free-firmware更换企业源
使用nano命令编辑pve-enterprise.list文件nano /etc/apt/sources.list.d/pve-enterprise.list
# 将原有的源链接在句首加 # 注释掉,更换以下清华源信息
deb https://mirrors.tuna.tsinghua.edu.cn/proxmox/debian bookworm pve-no-subscription更换Ceph源
使用nano命令编辑ceph.list文件nano /etc/apt/sources.list.d/ceph.list
# 将原有的源链接在句首加 # 注释掉,添加中科大ceph源
deb https://mirrors.ustc.edu.cn/proxmox/debian/ceph-quincy bookworm no-subscription更换CT容器源
# 备份APLInfo.pm
cp /usr/share/perl5/PVE/APLInfo.pm /usr/share/perl5/PVE/APLInfo.pm_back
# 替换为清华源:
sed -i 's|http://download.proxmox.com|https://mirrors.tuna.tsinghua.edu.cn/proxmox|g' /usr/share/perl5/PVE/APLInfo.pm
# 重启服务后生效
systemctl restart pvedaemon.service执行更新源
apt updateNTP同步
# 安装ntpdate
apt install ntpdate
# 使用阿里云 NTP 服务同步时间
ntpdate ntp.aliyun.com# 创建定时任务
crontab -e
# 输入1 使用nano命令编辑
# 在每周日00:00使用阿里云的NTP服务器同步系统时间
0 0 * * 0 ntpdate ntp.aliyun.com以上设置,分别在三台机器上执行。
配置网络
安装PVE时,网络这块不支持高级设置。所以需要安装好系统后在按前面规划好的架构去设置网络。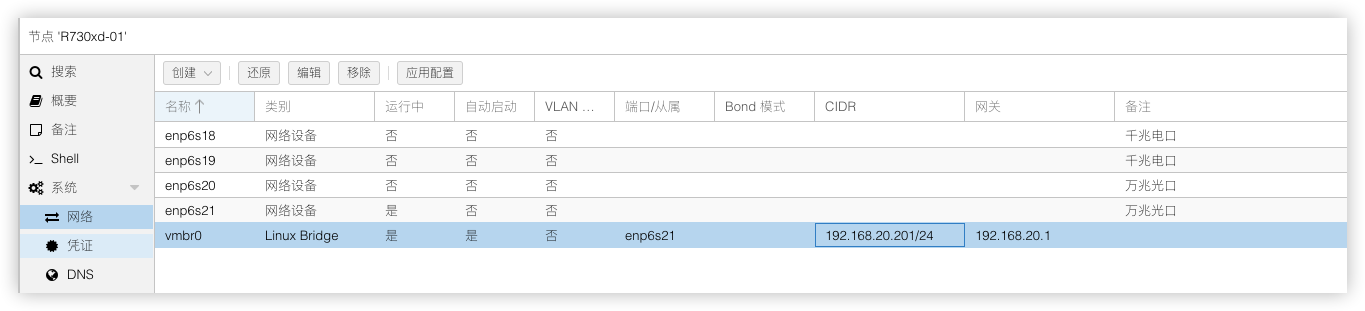
现在需要将2个千兆电口网卡enp6s18 enp6s19做端口聚合建立bond0模式使用LACP (802.3ad)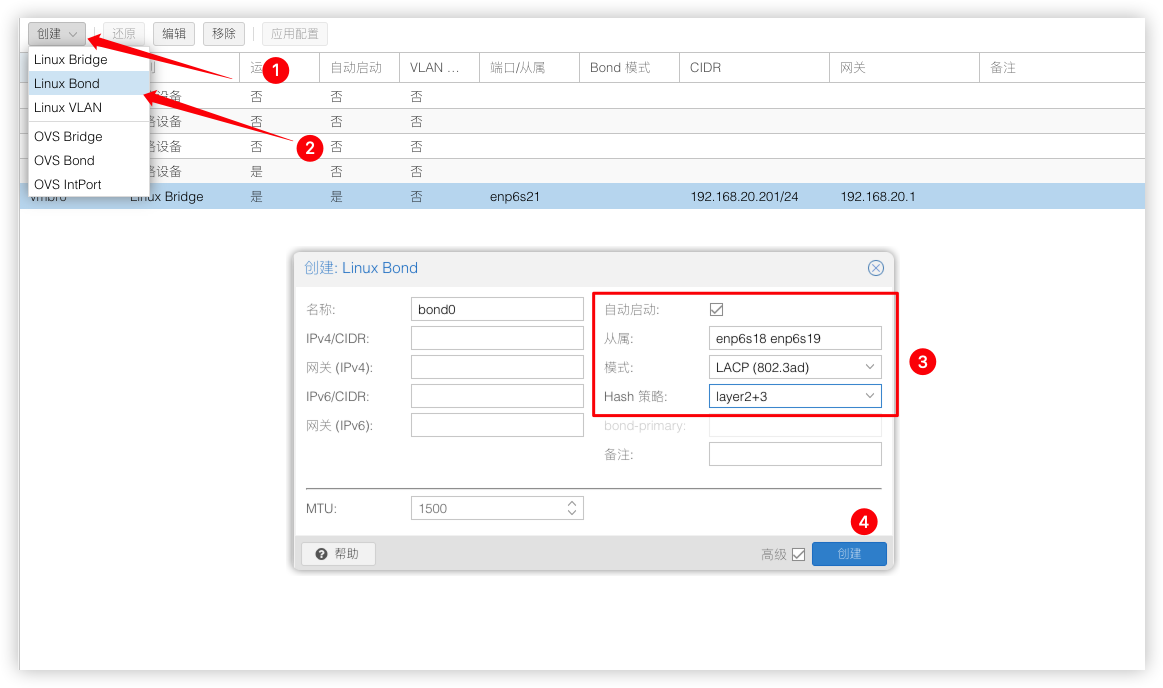
并建立个桥接vmbr1作为业务网络,桥接端口绑定在bond0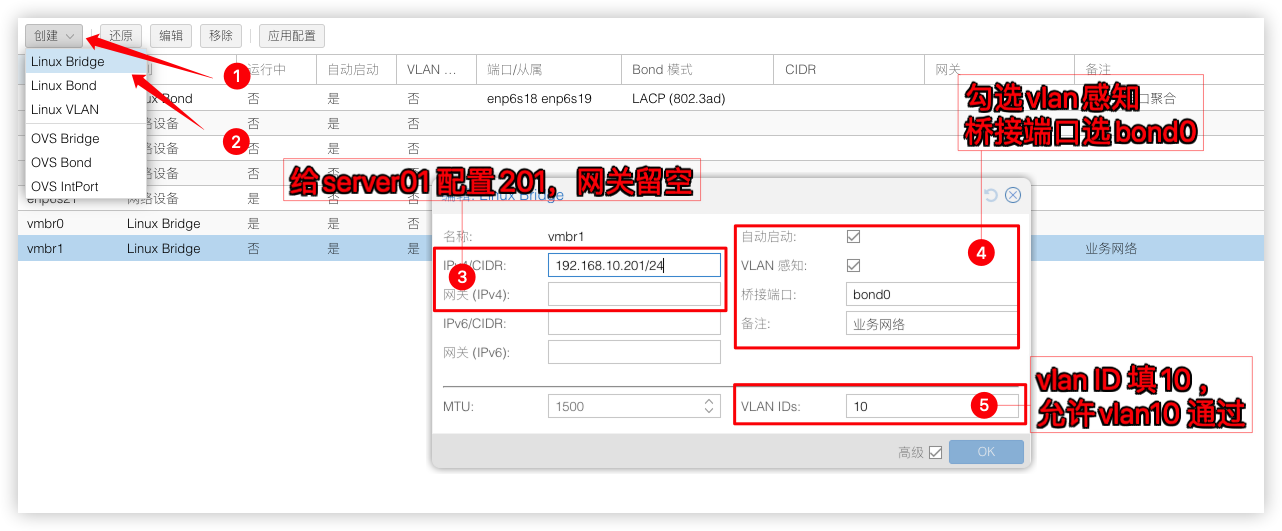
接着将2个万兆光口网卡enp6s20 enp6s21做端口聚合建立bond1模式使用LACP (802.3ad),建立前需要删除原先网卡 enp6s21绑定的桥接vmbr0否则无法建立bond1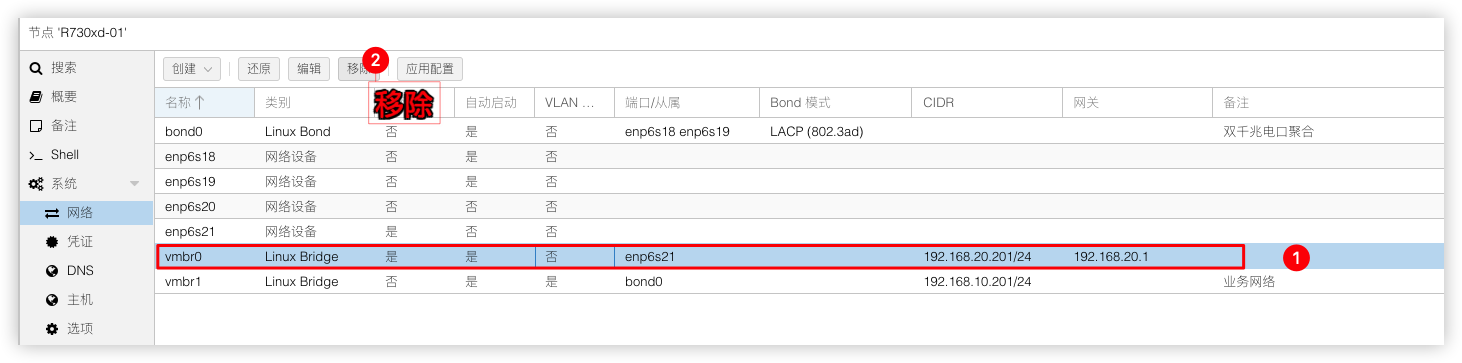
建立bond1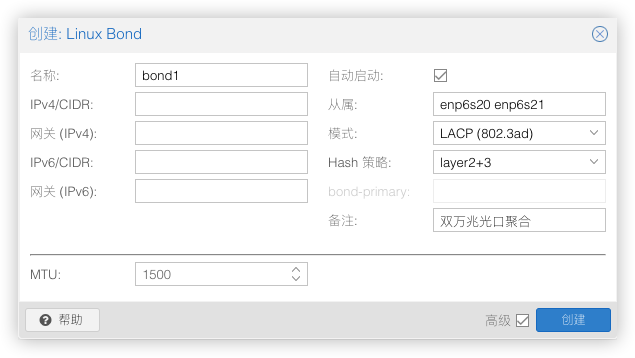
然后重新建立个桥接vmbr0作为管理网络,桥接端口绑定在bond1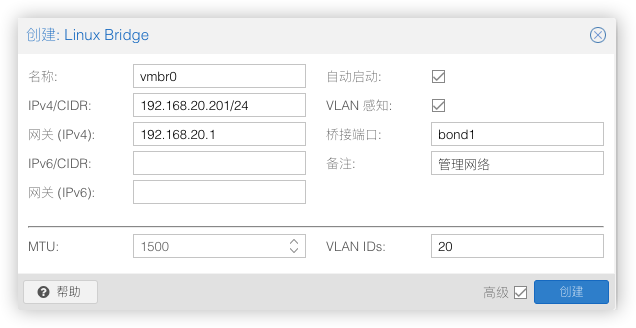
最终效果如下,全部配置没问题就点击应用配置,(交换机那边的设置省略,必须2边都设置好再点应用配置,不然PVE会失联无法访问)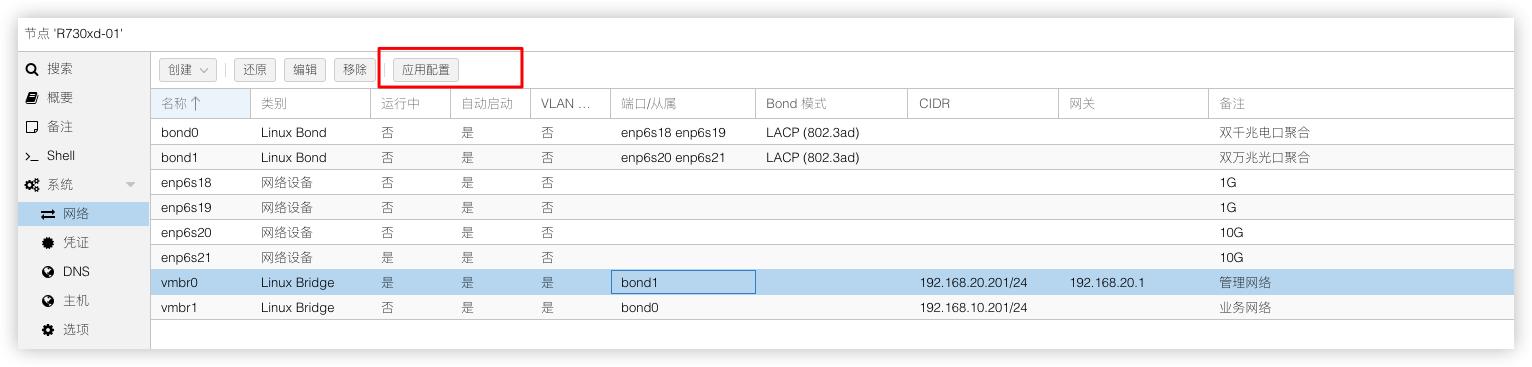
以上网络设置,分别在三台机器上配置。
| 设备 | 业务IP | 业务网关 | 管理IP | 管理网关 |
|---|---|---|---|---|
| server01 | 192.168.10.201/24 | 留空 | 192.168.20.201/24 | 192.168.20.1 |
| server02 | 192.168.10.202/24 | 留空 | 192.168.20.202/24 | 192.168.20.1 |
| server03 | 192.168.10.203/24 | 留空 | 192.168.20.203/24 | 192.168.20.1 |
集群配置
PVE初始化设置都设置好后,接着我们要将这3个PVE节点集中管理,在任意一个节点组建个集群,这里用server01创建集群,将server02,server03加入进来。
创建集群
在节点R730xd-01建立集群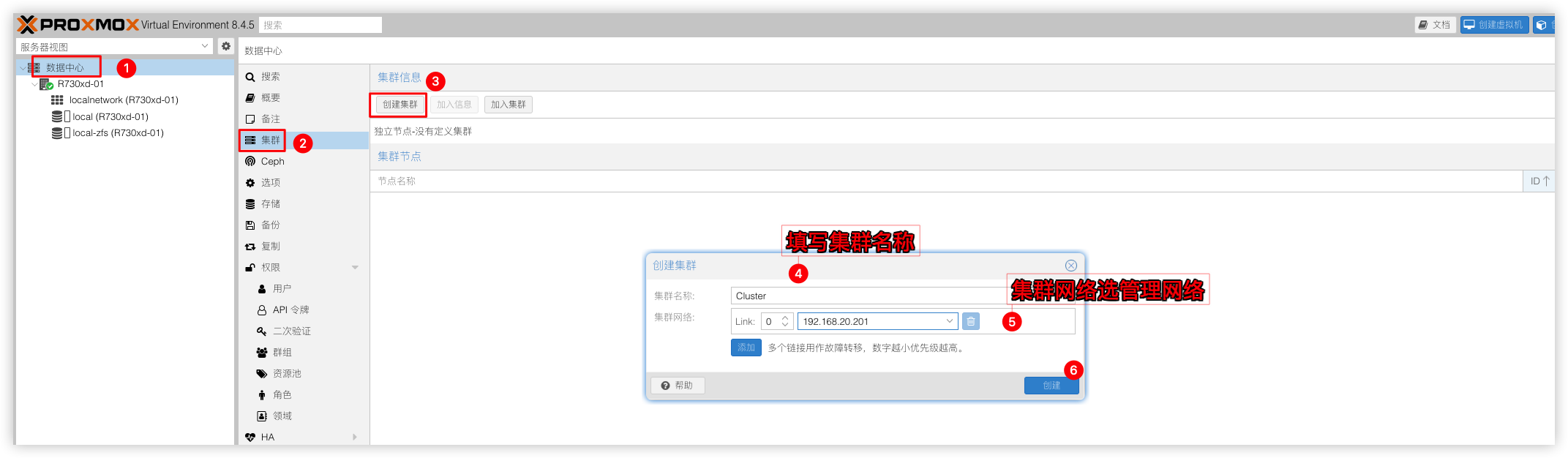
创建集群后,就可以将集群加入信息粘贴到节点R730xd-02节点R730xd-03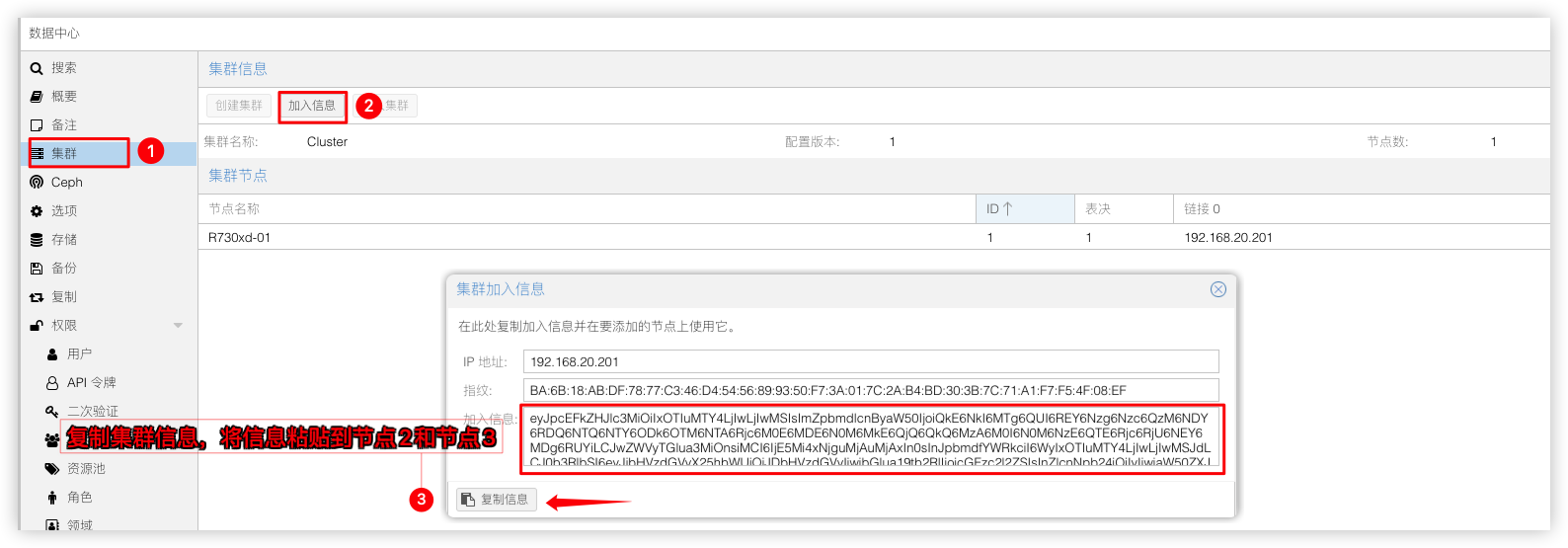
加入集群
分别吧节点R730xd-02节点R730xd-03加入到集群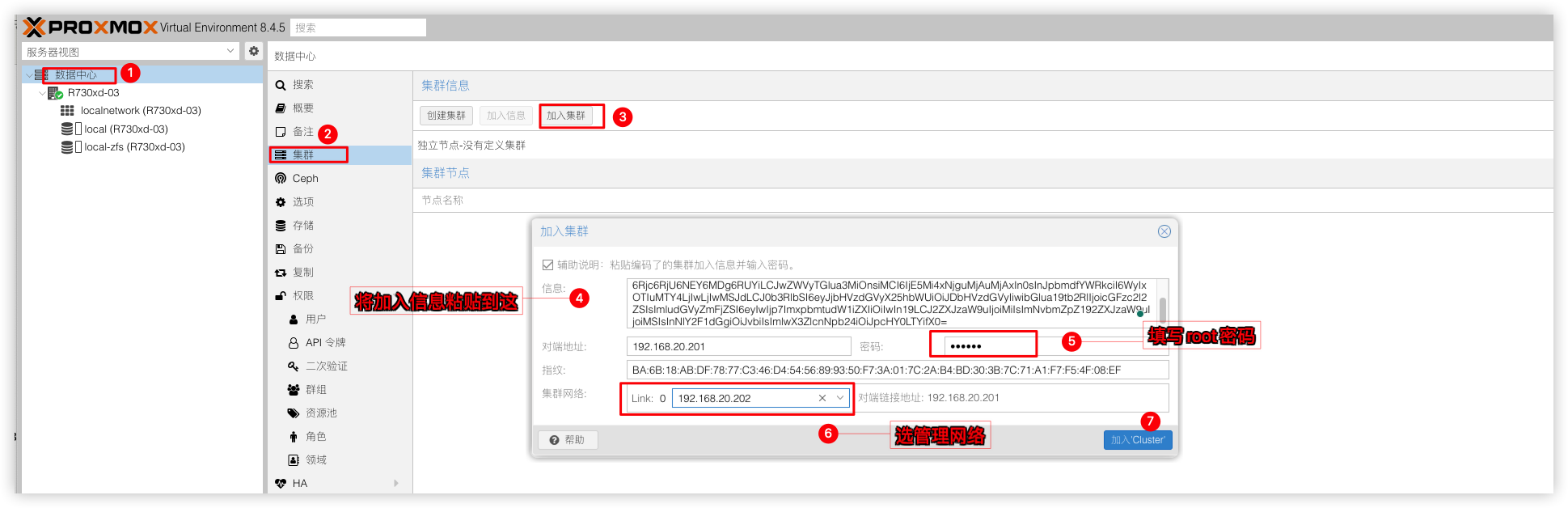
加入集群后,就可以从任意节点管理集群下的所有节点。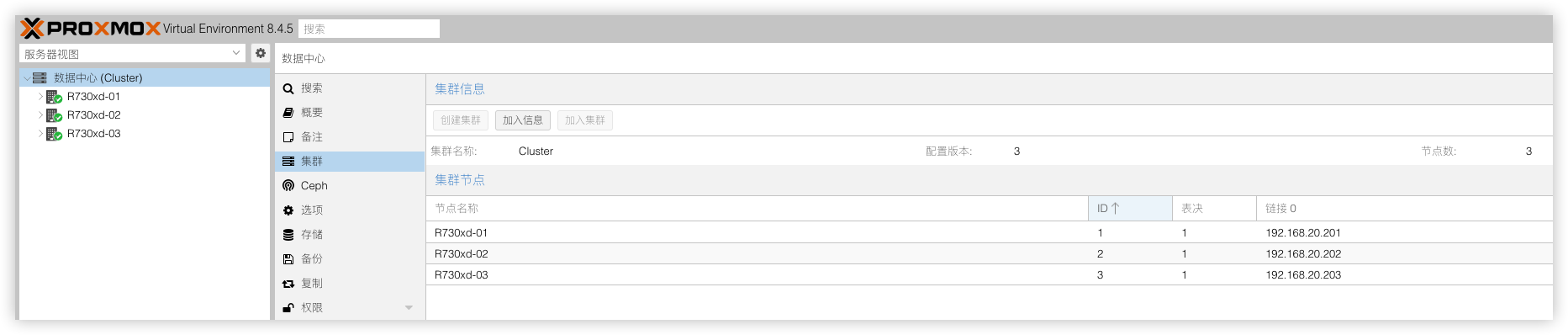
Ceph配置
集群加入进来后,继续配置Ceph分布式存储环节,同样的需要在3个节点上安装好Ceph软件,然后将硬盘加入OSD。
安装Ceph
分别在节点R730xd-01节点R730xd-02节点R730xd-03上安装Ceph软件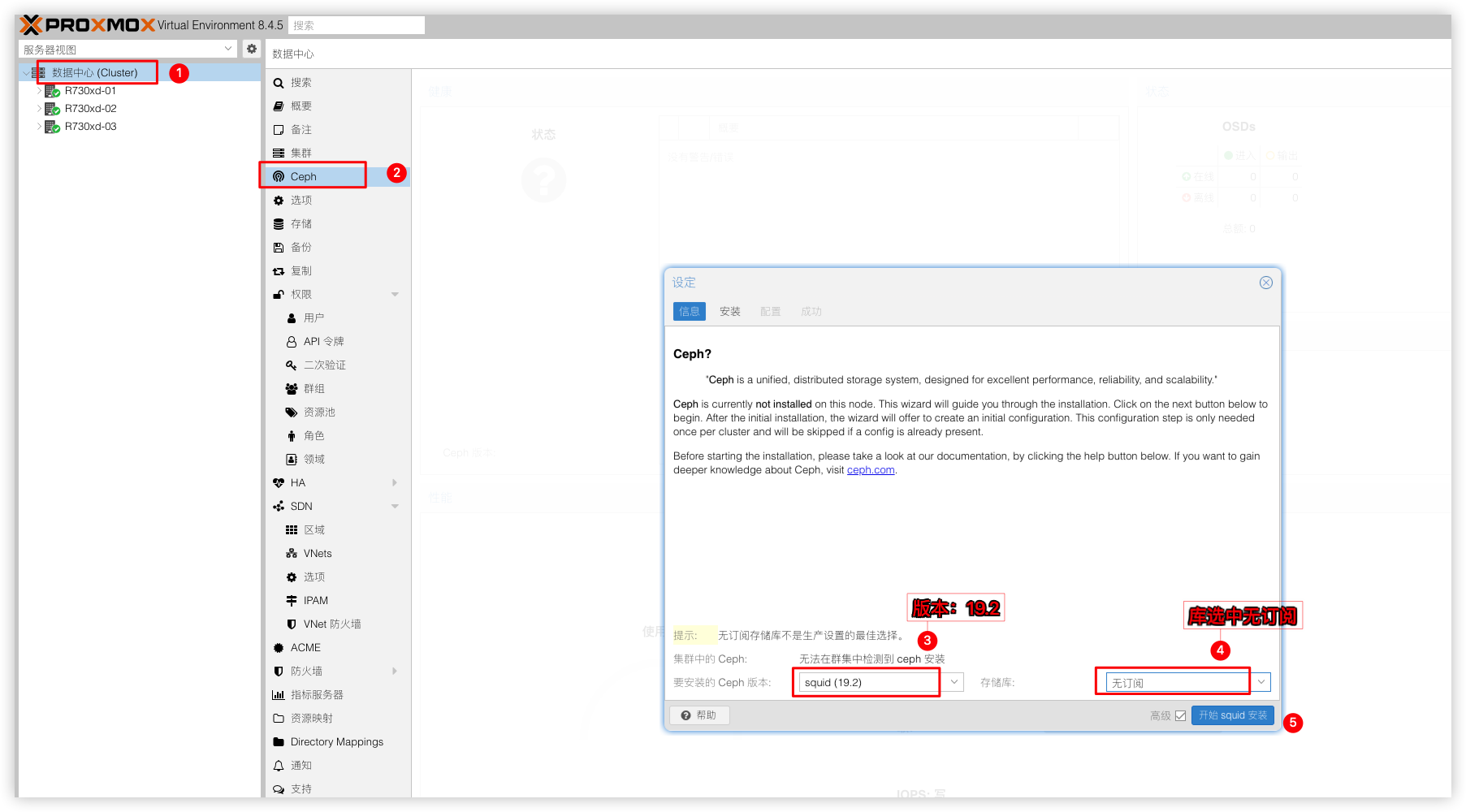
输入y继续安装,Ceph公共网络选业务vlan,Ceph集群网络选管理vlan。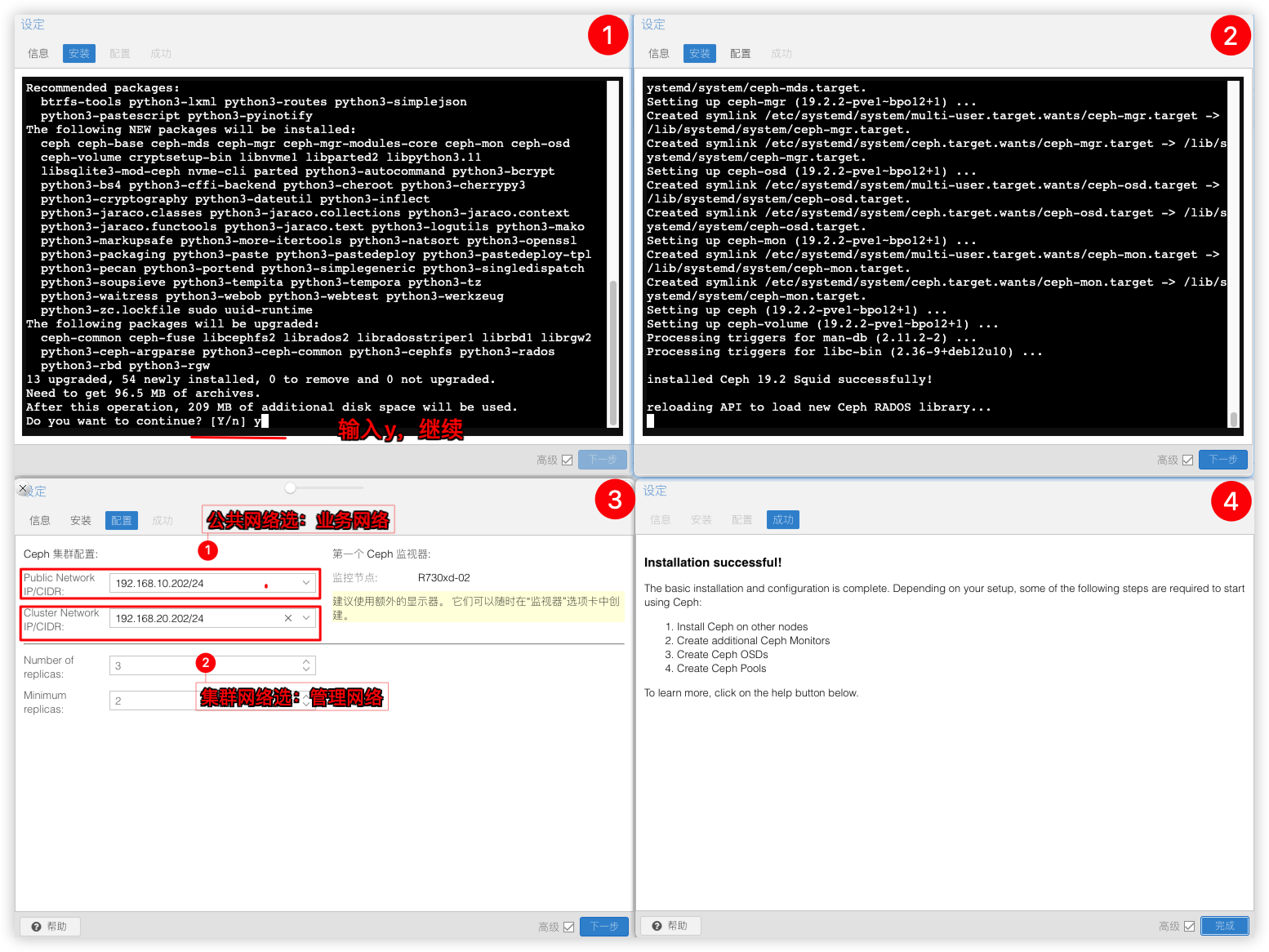
Ceph 网络简介
Public Network:公共网络主要用于客户端与 Ceph 集群之间的通信,负责处理客户端流量以及 Ceph MON 通信。Cluster Network:集群网络主要用于 Ceph 集群内部通信,负责处理 OSD 心跳、复制、回填和恢复流量。创建MON节点
为了避免主监控节点宕机,Ceph的状态无法查看,需要将其他节点加入到监视器里面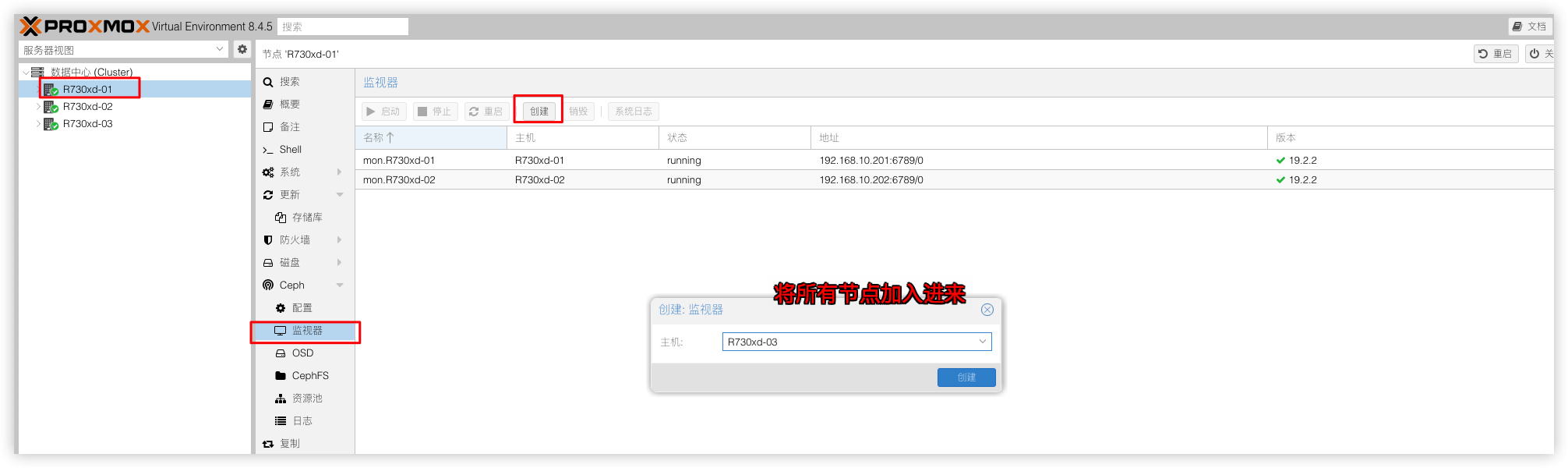
创建MRG节点
再以同样的方法创建MGR节点,MGR节点因为同时只能存在一个,所以这里的三个MGR节点互为主备,当主MGR出现故障时自动切换到备MGR,以实现高可用性。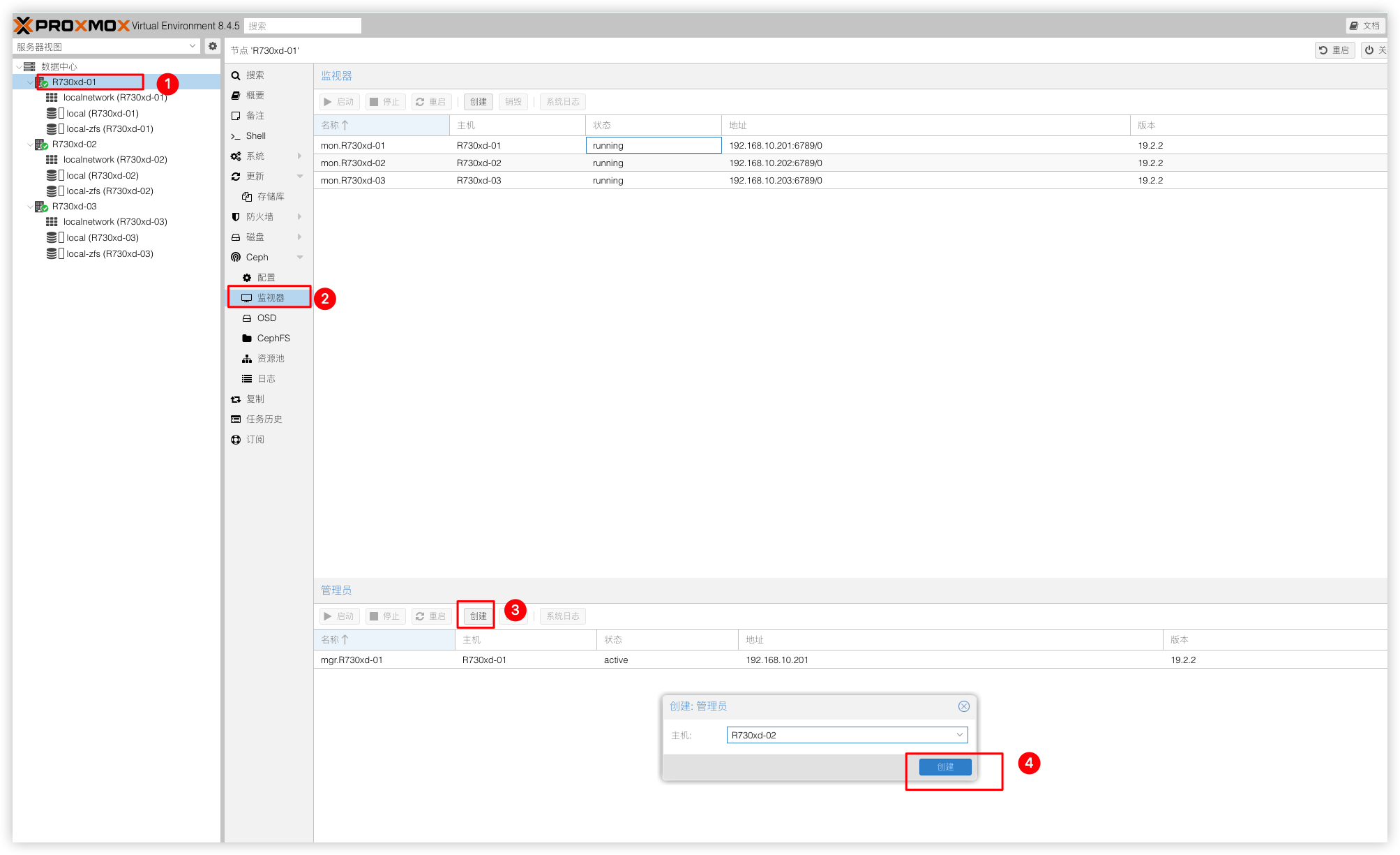
创建OSD磁盘
依次给3个节点添加OSD磁盘。将剩下的1TB Nvme和3块8tb sata创建为OSD磁盘(硬盘需要擦除清空才能添加)。其中的DB磁盘和WAL磁盘可以理解为缓存加速,硬盘本身是机械硬盘可以设置一下。需要而外使用nvme/ssd这类硬盘来做缓存。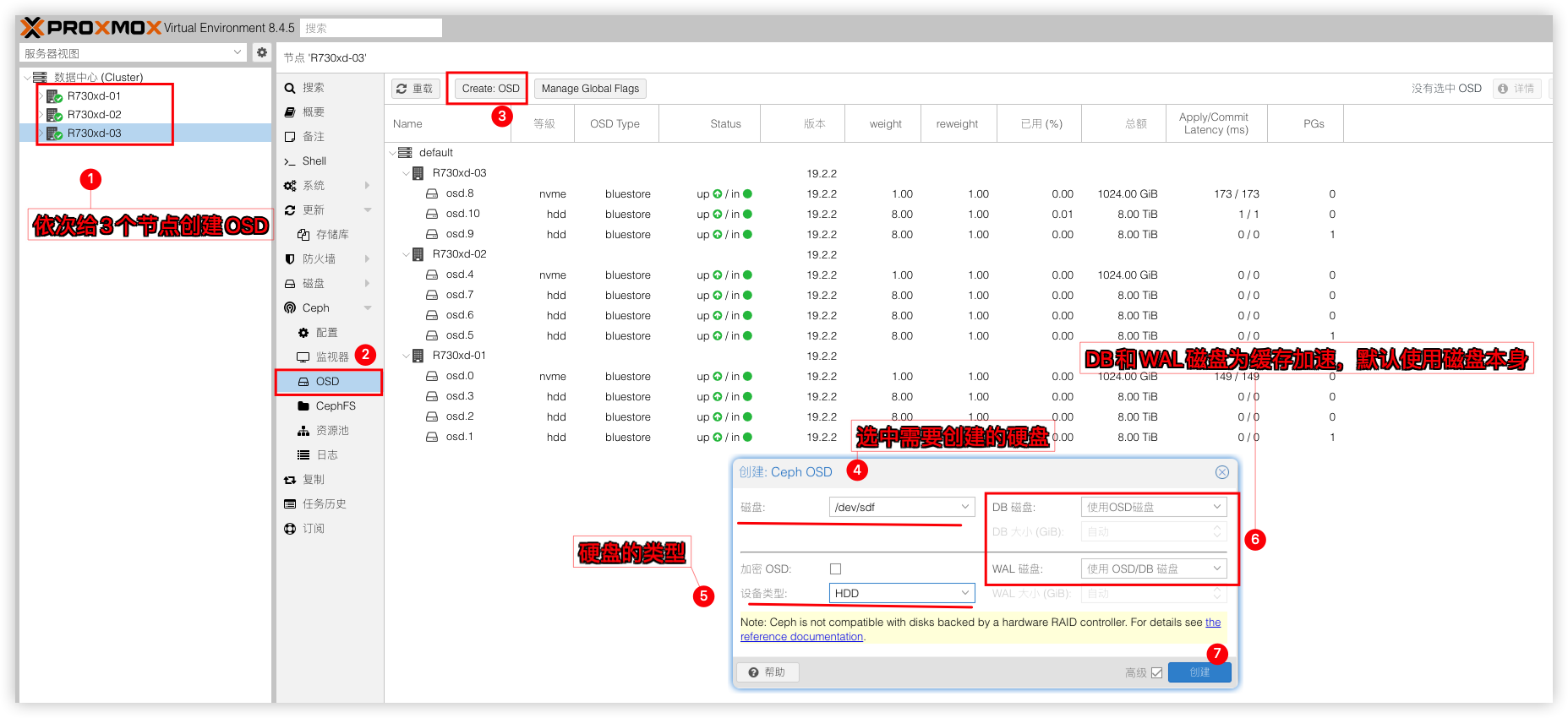
关于DB/WAL磁盘的作用和特点
DB磁盘作用
a. 元数据存储:存储对象元数据、对象映射和磁盘分配状态
b. 快速查询:加速对象查找和定位
c. 减少主存储访问:通过缓存元数据减少对主存储设备的访问
特点
a. 通常需要OSD容量的1-4%作为DB空间
b. 对IOPS要求高,建议使用SSD
c. 可以多个OSD共享同一个物理DB设备
WAL磁盘作用
a. 写操作缓冲:WAL磁盘记录了所有即将写入主存储的数据变更
b. 崩溃恢复:在系统意外崩溃时,可以通过WAL恢复未完成的操作
c. 顺序写入优化:将随机写操作转换为顺序写,提高SSD寿命和性能
特点
a. 通常只需要1-10GB容量(即使对于TB级OSD)
b. 对延迟极其敏感,建议使用高性能NVMe SSD
c. 每个OSD有自己独立的WAL
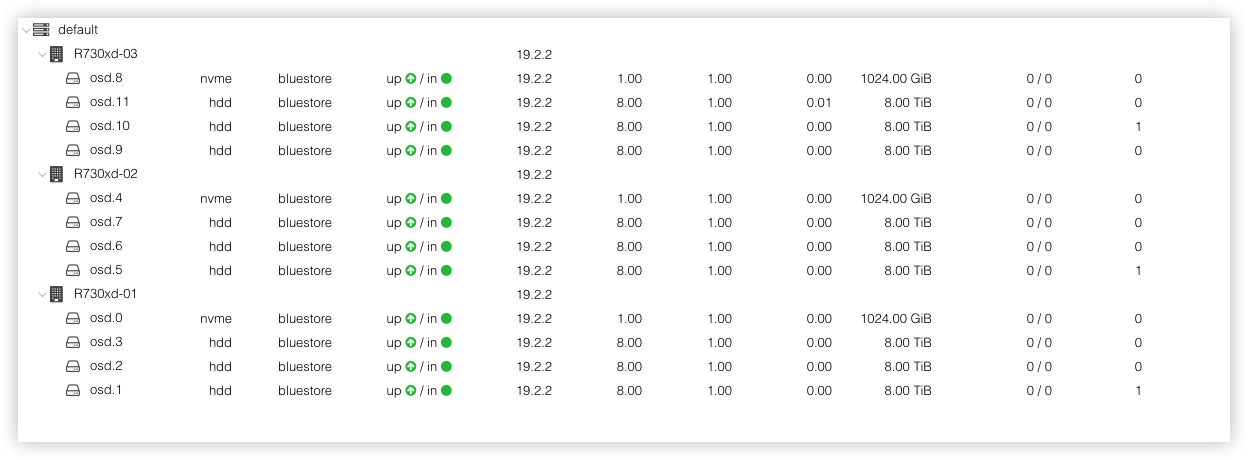
配置完毕后就可以在列表中看到全部的12个OSD磁盘
创建Ceph FS
在需要创建虚拟机备份、ISO镜像或者容器模板时需要使用CephFS存储,所以这里来创建个CephFS。
先在元数据服务器栏选择创建为每台机器建立MDS节点然后点击上方创建CephFS即可。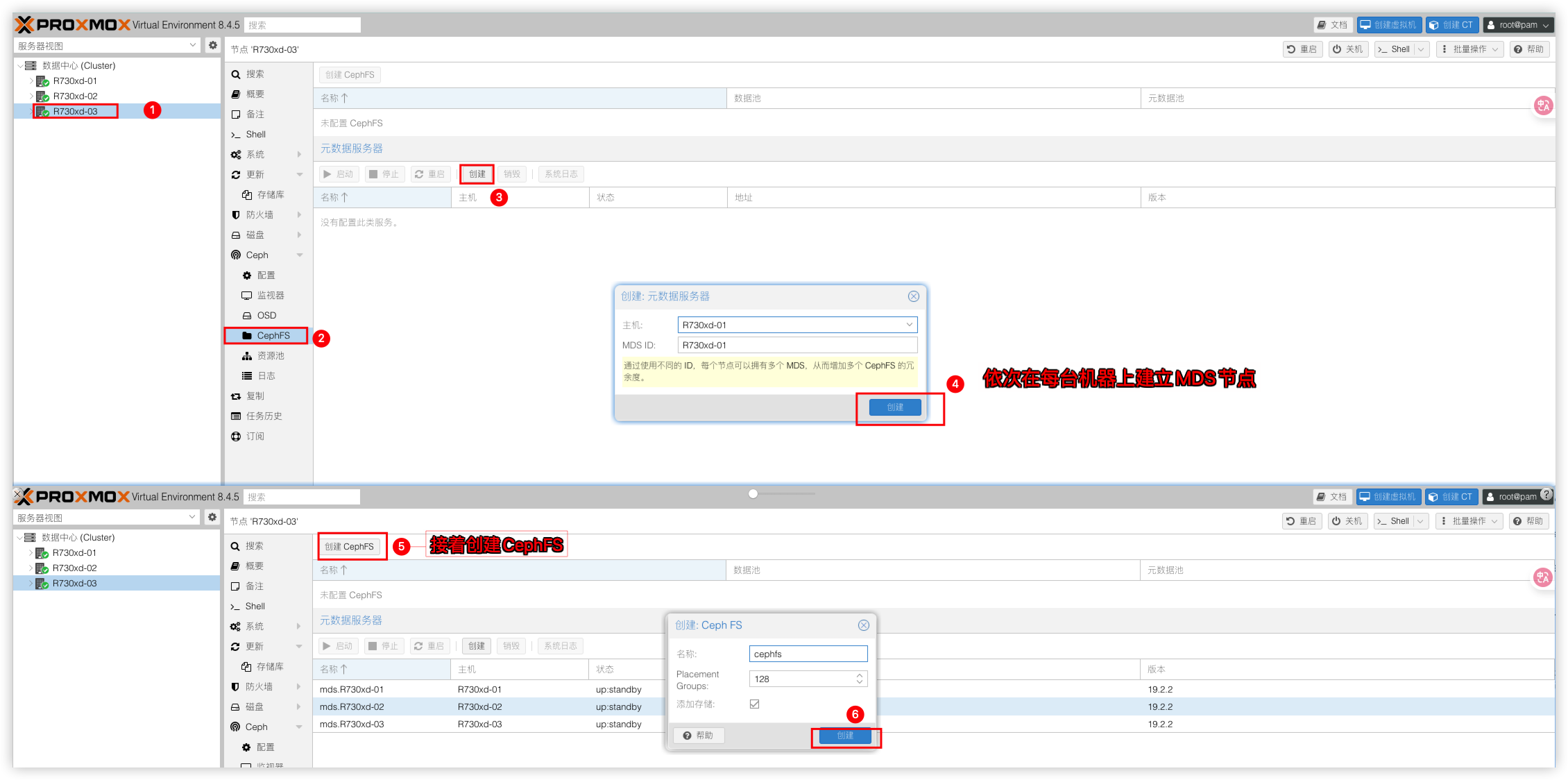
创建Ceph Pool
在需要创建虚拟机磁盘或者容器磁盘时需要使用Ceph Pool资源池,所以这里来创建个Ceph Pool。
区分Ceph硬盘类型
由于OSD磁盘有NVMe和HDD这2种类型磁盘,Nvme磁盘打算是用于虚拟机系统盘,HDD磁盘则为数据盘。所以这里需要先创建2条规则用于区分Ceph Pool硬盘类型。在PVE Shell中执行:
# 列出OSD磁盘类型
ceph osd tree
# 创建规则HDD_rule,并指向标记为HDD的OSD磁盘
ceph osd crush rule create-replicated HDD_rule default host hdd
# 创建规则NVMe_rule,并指向标记为NVMe的OSD磁盘
ceph osd crush rule create-replicated NVMe_rule default host nvme创建Ceph-NVMe
创建名为Ceph-NVMe的资源池,规则选NVMe_rule副本大小为3个,最小副本为2个,这样分配的资源池3台节点的存储只能使用1个节点的存储数据以确保不会发生数据丢失。(不要将最小副本数设置为1。为1时的复制池允许在对象只有1个副本时对其进行 I/O,这可能会导致数据丢失PG不完整或找不到对象。)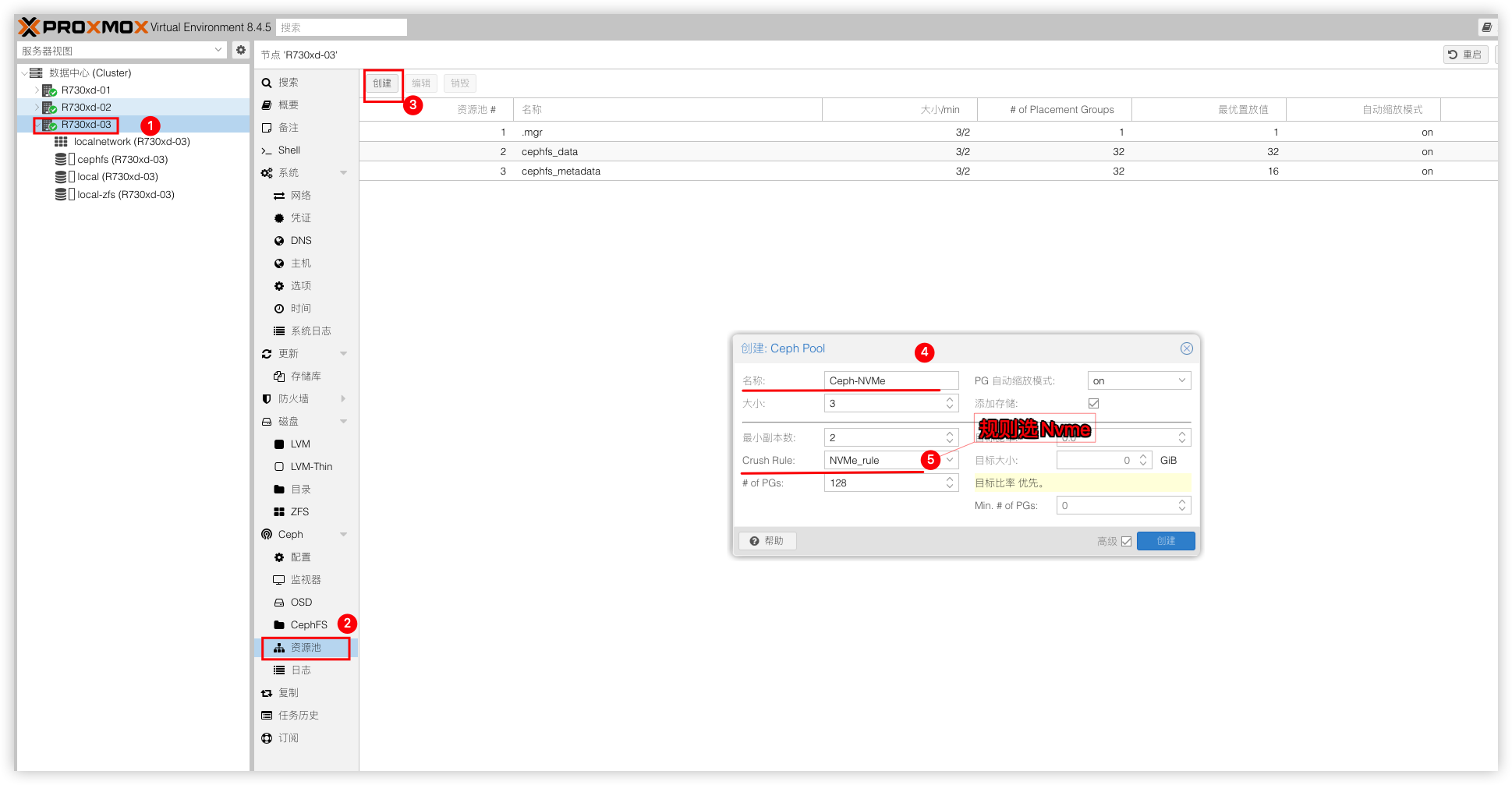
创建Ceph-HDD
创建名为Ceph-HDD的资源池,规则选HDD_rule副本大小为3个,最小副本为2个,这样分配的资源池3台节点的存储只能使用1个节点的存储数据以确保不会发生数据丢失。(不要将最小副本数设置为1。为1时的复制池允许在对象只有1个副本时对其进行 I/O,这可能会导致数据丢失PG不完整或找不到对象。)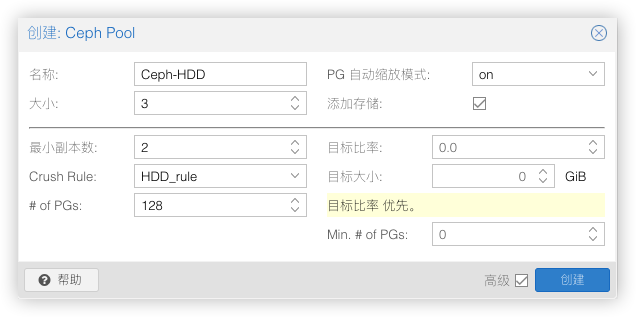
通过规则创建出来的资源池硬盘就区分开了,容量也是对的上的。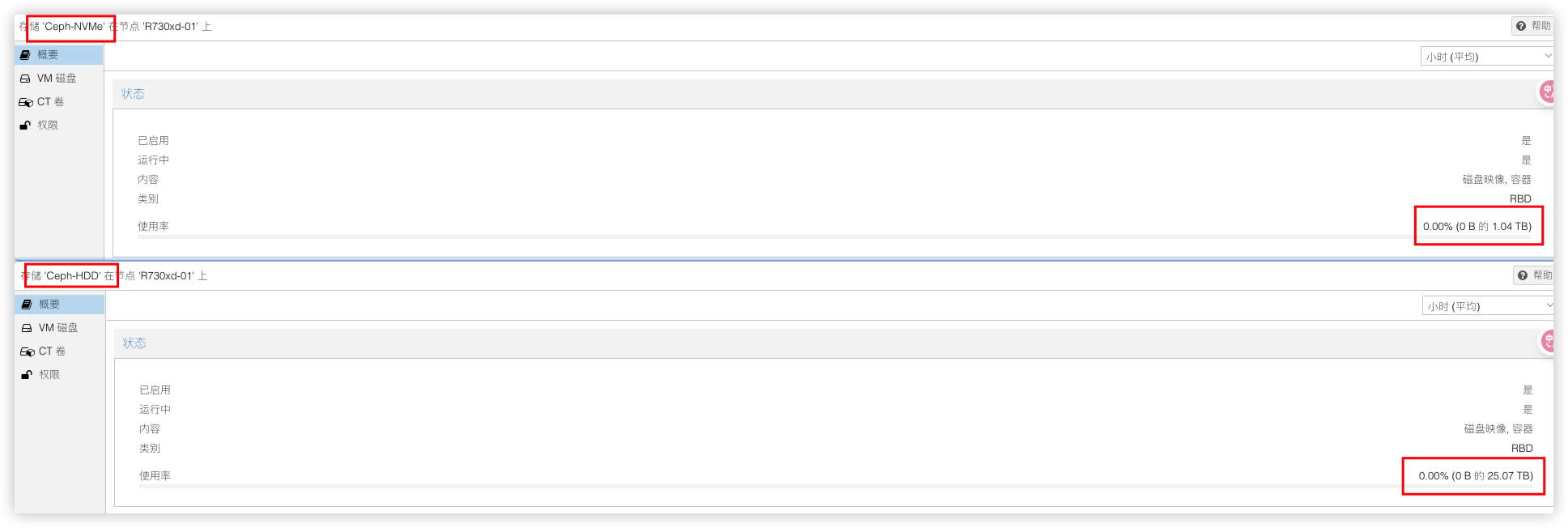
创建虚拟机
来创建个虚拟机,将磁盘存储在Ceph-NVMe或者Ceph-HDD的存储池,虚拟机就能在各个节点热迁移了。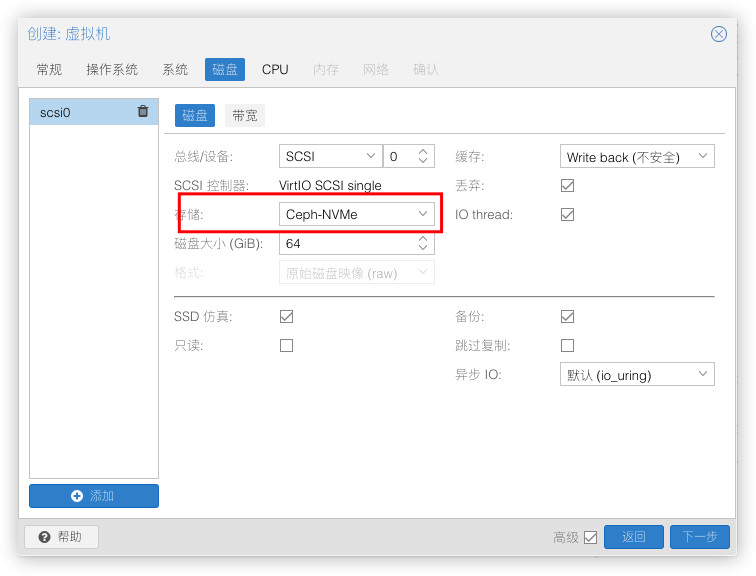
选中需要迁移到的节点,虚拟机就能在该节点上运行。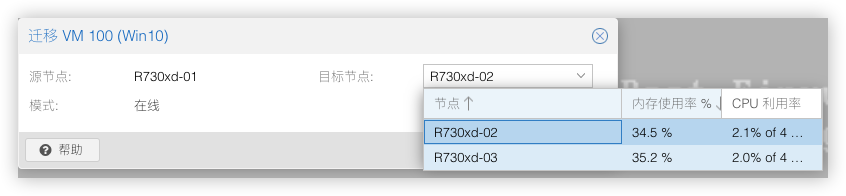
HA配置
Ceph的分布式存储配置好后,最后在来配置HA高可用。哪天节点断电或者故障,故障节点里面运行的VM是没法自己迁移到其他正常节点上的,这时就需要用到HA组件了。即使在发生故障时也可以继续提供服务,减少停机时间,唯一不足地方是没法保留虚拟机之前状态,HA会将故障节点的VM迁移到正常节点上并重新开机。步骤:数据中心 → HA → 群组 → 创建 → 配置个群组并勾选需要的节点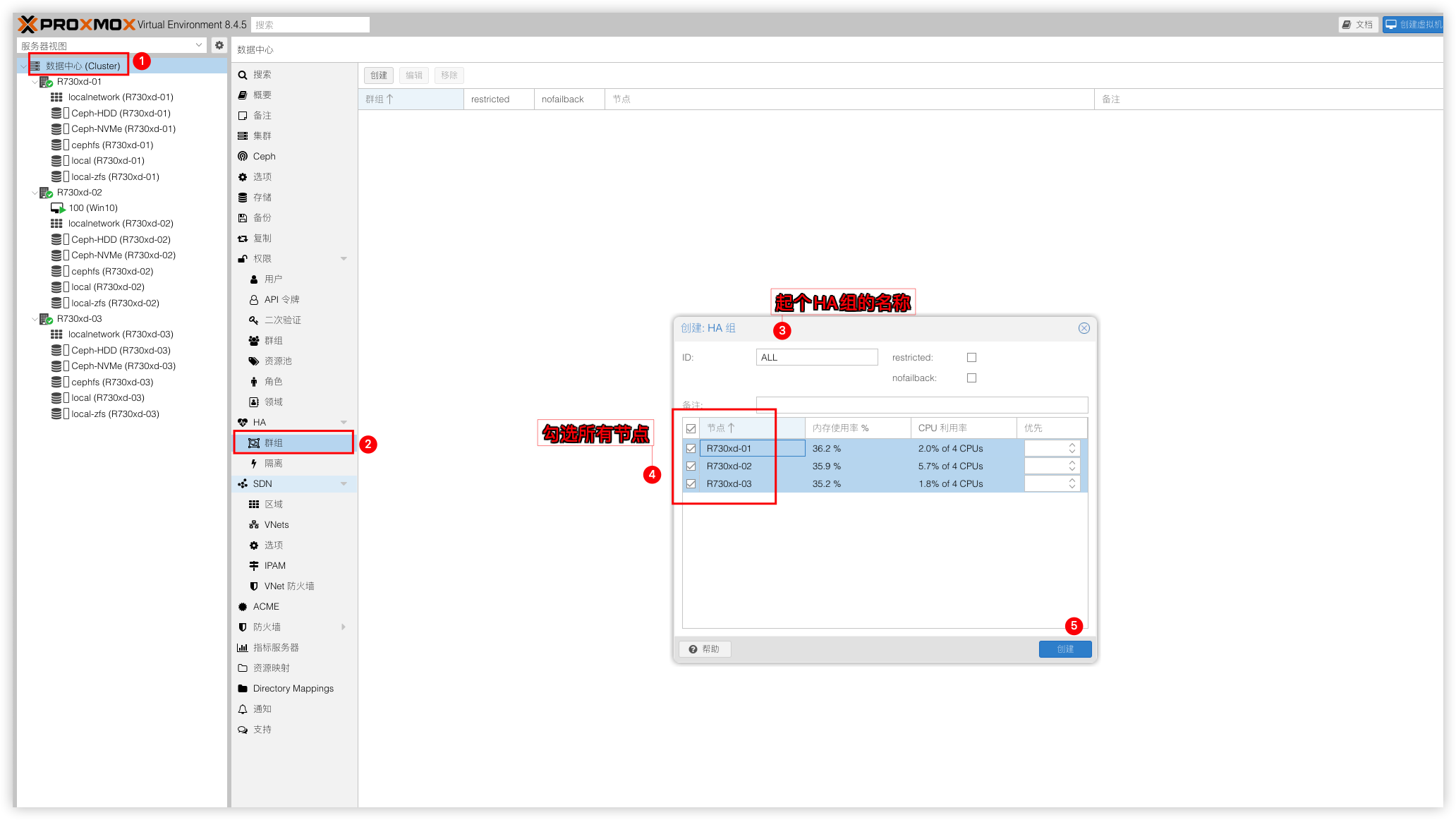
最后把需要加入HA的虚拟机加入到这个群组,选择该虚拟机下的节点服务器,关机或断开网络,去验证虚拟机是否在其他节点自动重启。成功说明HA已经生效了。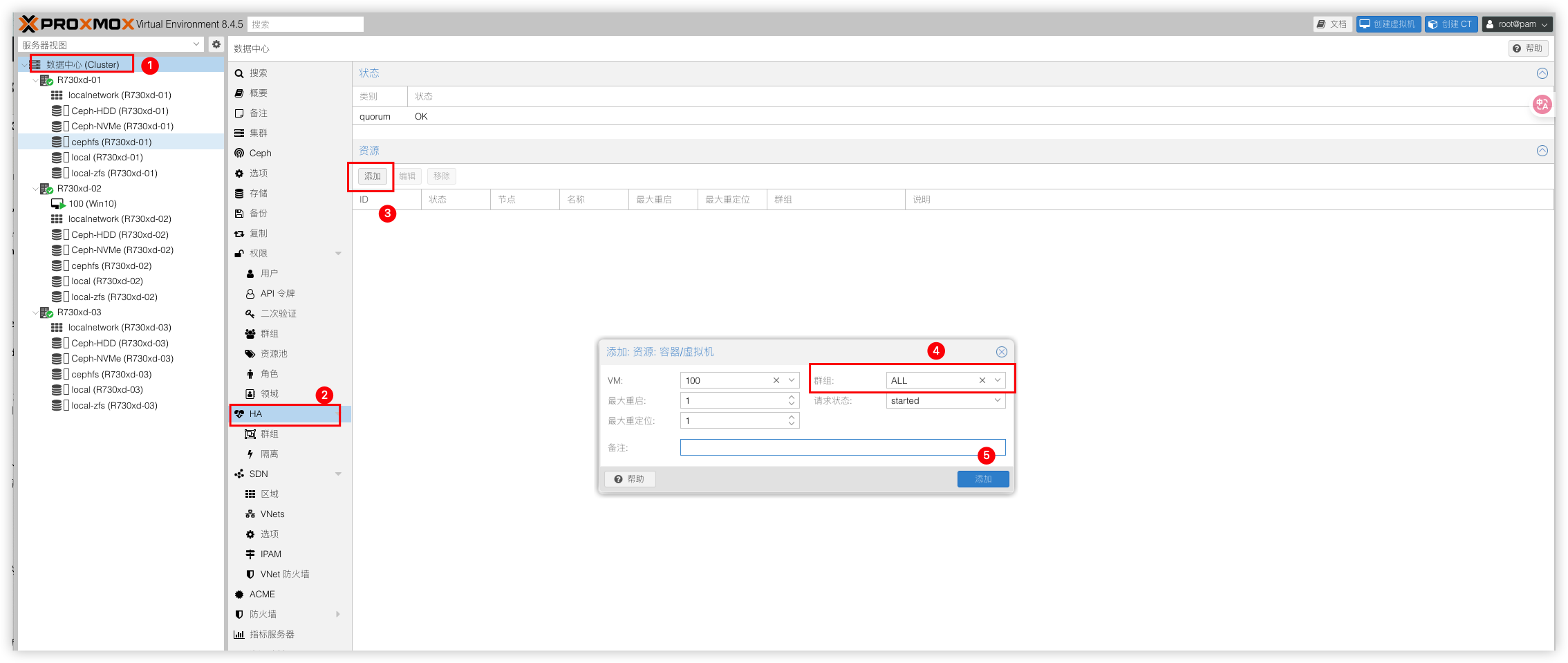
结语
看到这,恭喜你现在已经成功部署了一个基于Proxmox VE和Ceph的高可用分布式存储系统。这个架构能够提供虚拟机的高可用性、存储的冗余和出色的扩展性。


5 条评论
之套服务器的待机功耗,一天估计会到18KWh左右吧,跑满业务的话就算飙不到30,估计也差不多少了。
多谢,多谢
这样一套三台服务器,即使是二手的也要不少钱吧
明说吧,组一套多少钱?功耗多少?
本来选了一套 all in one 自己diy的nas,看了你的这个瞬间不香了
此外 二手设备可能并不贵,千元级别就可用达到(不算磁盘),但功耗也不是你愿意承担的。
all in one 本身就是个人用户低成本的选择,这个是企业级的,本身就不匹配啊。
all in one 主要是低成本,数据安全,这个是高可用的数据安全,当然成本不一样了。